Linux零拷贝不是什么新知识点了,网上资料一大堆,这是2021年我要在公司做一次分享,就写了这篇文章,图片很多是来源于网络。
一、零拷贝的由来和定义
1. 基本概念
内核态:Ring0级别,运行在内核空间中,可以执行任何操作并且在资源的使用上没有限制。
用户态:Ring3级别,运行在用户空间中,访问资源受限。

内核缓冲区:Page Cache,在操作系统级别,提高磁盘IO效率,优化磁盘文件的读写操作。
读文件:
time cat rocket.log >/dev/null
执行时间:
real 0m9.797s
user 0m0.085s
sys 0m2.546s
查看缓存情况 vmtouch rocket.log :
Files: 1
Directories: 0
Resident Pages: 240561/240561 939M/939M 100%
Elapsed: 0.020697 seconds
再次执行cat:
real 0m0.138s
user 0m0.009s
sys 0m0.130s
写文件:
将更改数据写入到PageCache,并标记为dirty,随后操作系统负责将数据刷新到磁盘中。 回写机制包括: write back和write through。
异步刷盘:
dd if=/dev/zero of=async_write.txt bs=64M count=16 iflag=fullblock 记录了16+0 的读入记录了16+0 的写出1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.903126 s, 1.2 GB/s同步:
dd if=/dev/zero of=sync_write.txt bs=64M count=16 iflag=fullblock oflag=sync记录了16+0 的读入记录了16+0 的写出1073741824 bytes (1.1 GB, 1.0 GiB) copied, 8.959 s, 120 MB/s
用户缓冲区:目的是为了减少系统调用次数,从而降低操作系统在用户态与核心态切换所耗费的时间。在读取文件时,会先申请一块内存数组buffer,然后每次调用read,读取一定字节长度的数据,写入buffer。
Socket缓冲区:Socket输入缓冲区和输出缓冲区。
2. IO传输过程
在 Linux 系统中,标准的文件读写方式是通过 write() 和 read() 两个系统调用函数实现的,通过 read() 函数读取文件到到缓冲区中,然后通过 write() 方法把缓存中的数据输出到网络端口
int read (int fd,void*buff,int size);
int write ( int fd,void *buff ,int datalen);

Step1:read 系统调用会触发从用户态到内核态的上下文切换,随后如果PageCache没有缓存数据, 就执行磁盘文件数据拷贝过程。
- 由 CPU 通过设备驱动程序向设备寄存器写入一个通知信号,告知设备控制器要读取数据;
- 设备控制器启动磁盘读取的过程,把数据从磁盘拷贝到磁盘缓冲区里;
- 完成后,磁盘控制器通过中断控制器发出IO中断信号;
- CPU收到信号后,停止当前工作,保护当前上下文,然后从地址总线取出设备编号,通过编号找到中断向量所包含的中断服务的入口地址,压入 PC 寄存器,开始运行磁盘中断服务,把数据从磁盘控制器的缓冲区拷贝到内核缓冲区;
Step2: CPU将数据从内核缓冲区拷贝到用户缓冲区,read系统调用返回,并完成从内核态到用户态的上下文切换。
Step3:执行write调用,用户态再次切换到内核态,CPU执行从用户缓冲区到Socket缓冲区的数据拷贝,随后再将数据拷贝到网卡中,write调用返回。
整个文件数据传输过程,CPU完成4次的数据拷贝,并存在多次的上下文切换。
DMA优化:
DMA控制器,直接存储器存取,是一种用来提供在外设和存储器之间的高速数据传输。整个过程无须 CPU 参与,数据直接通过 DMA 控制器进行快速地移动拷贝,节省 CPU 的资源去做其他工作。(图片来源于网络)
工作流程:
1、进程发起read调用,用户态切换到内核态,CPU会将内核缓冲区地址和磁盘地址写入到DMA控制器的寄存器中;
2、DMA控制器会通知磁盘控制器执行磁盘读取的流程,随后会引导磁盘控制器将数据传输到寄存器中的内核缓冲区的地址。执行完成后会返回一个ack给DMA控制器;
3、DMA收到ack信号后,会通过中断控制器向CPU发送一个中断信号;
4、CPU收到信号后,会保护好当前上下文,并执行从内核缓冲区到用户缓冲区的数据拷贝,随后切换到用户态。
5、进程发起write调用,上下文由用户态切换到内核态,CPU执行用户空间到Socket缓冲区的拷贝。
6、DMA控制器完成从Socket缓冲区到网卡的数据拷贝。
7、write执行完成,并切换回用户态。
通过引入DMA,使得在整个read/write调用过程中减少了两次CPU拷贝过程,在我们外设和主存之间的数据拷贝不再需要CPU的参与。
3. 传统IO传输的弊端
虽然通过引入 DMA,已经把 Linux 的 整个I/O 传输过程中的 CPU 拷贝次数从 4 次减少到了 2 次,但是仍然存在内核缓冲区和用户缓冲区之间的CPU 拷贝。同时系统调用引起的上下文切换在一定程度也影响了系统性能。特别是那些频繁 I/O 的场景,频繁的CPU 拷贝以及上下文切换都会降低整体性能。
上下文切换的代价:
- 保留用户态现场(上下文、寄存器、用户栈等)
- 复制用户态参数,用户栈切到内核栈,进入内核态
- 额外的检查(因为内核代码对用户不信任)
- 执行内核态代码
- 复制内核态代码执行结果,回到用户态
- 恢复用户态现场(上下文、寄存器、用户栈等)
为了降低、甚至是完全避免 CPU 拷贝,降低上下文切换的次数,零拷贝技术应运而生!
4. 零拷贝的定义
Wikipedia定义:
"Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
零拷贝技术主要是指当计算机在执行操作时,CPU并不需要将数据从某个内存区域移动到另外一个区域,其能够在进行网络文件传输时节省CPU周期和内存带宽。
零拷贝作用:
- 减少或避免不必要的CPU数据拷贝,从而释放CPU去执行其他任务
- 减少用户态和内核态的上下文切换
- 减少内存的占用
二、零拷贝的分类
在 Linux 中零拷贝技术主要有 3 个实现思路:绕过内核缓冲区的直接 I/O、减少数据拷贝次数以及写时复制技术。(图片来源于网络)

1、绕过内核缓冲区的直接IO
思想:直接绕过内核缓冲区,数据直接从用户空间写入到磁盘中。
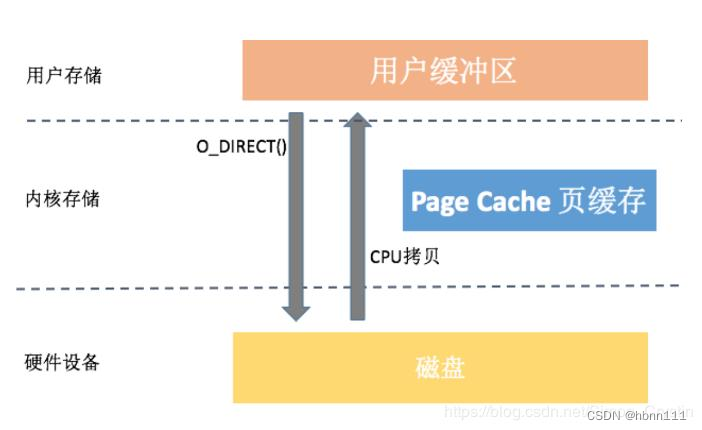
要在块设备中执行直接 I/O,进程必须在打开文件的时候设置对文件的访问模式为 O_DIRECT,这样就等于告诉操作系统进程在接下来使用 read() 或者 write() 系统调用去读写文件的时候使用的是直接 I/O 方式,所传输的数据均不经过内核缓冲区。
int open(const char *pathname, int flags, mode_t mode);
dd if=/dev/zero of=sync_write.txt bs=64M count=16 iflag=fullblock oflag=direct优点:完全避免了内核空间和用户空间的数据拷贝,如果传输的数据量很大,可大大提高性能。
缺点:如果数据不在应用程序缓存中,每次都会直接从磁盘加载,导致异常缓慢。
谁会使用直接IO?
自缓存应用程序
对于某些应用程序来说,它会有它自己的数据缓存机制,比如,它会将数据缓存在应用程序地址空间,这类应用程序完全不需要使用操作系统内核中的高速缓冲存储器,这类应用程序就被称作是自缓存应用程序( self-caching applications )。
例如,应用内部维护一个缓存空间,当有读操作时,首先读取应用层的缓存数据,如果没有,那么就通过 Direct I/O 直接通过磁盘 I/O 来读取数据。缓存仍然在应用,只不过应用觉得自己实现一个缓存比操作系统的缓存更高效。
实际应用:自缓存应用,数据库,如Mysql。


2、减少甚至避免用户空间和内核空间的数据拷贝
1、mmap
内存映射,memory map,将一个进程的地址空间中的一段虚拟地址映射到磁盘文件地址。
mmap的目的是将内核缓冲区与用户缓冲区进行映射,从而实现内核缓冲区与应用程序内存的共享。大致的流程如下图所示:

- 用户进程系统调用 mmap(),从用户态陷入内核态,将内核缓冲区映射到用户缓冲区;
- DMA 控制器将数据从磁盘缓冲区拷贝到内核缓冲区;
- mmap() 返回,上下文从内核态切换回用户态;
- 用户进程调用 write(),再次陷入内核态;
- CPU 将内核缓冲区中的数据拷贝到套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
- write() 返回,上下文从内核态切换回用户态。
优点: 相比于传统的read_write系统调用,内存映射机制不需要将内核缓冲区数据拷贝到用户缓冲区,即少了一次CPU拷贝,节省内存。
Rocketmq在commitLog、ConsumeQueue等文件读写时使用了mmap+write的方式,主要通过MappedByteBuffer 对文件进行读写操作。其中,利用了 NIO 中的 FileChannel 模型将磁盘上的物理文件直接映射到用户态的内存地址中。
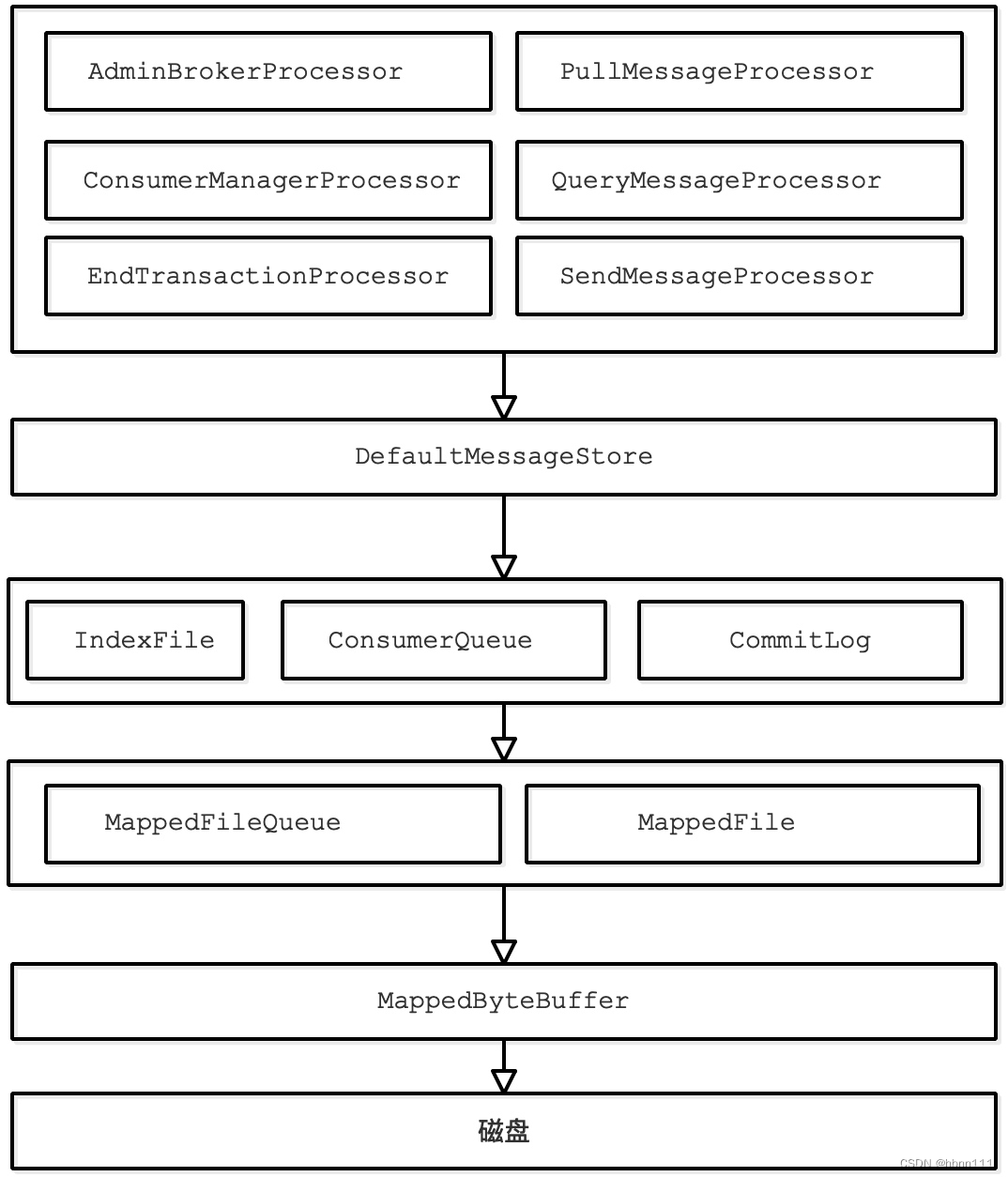
MappedFile(负责将消息写入Page Cache缓冲区中(commit方法),或者将消息刷入磁盘(flush)):

MappedByteBuffer内存映射机制有个限制,一次只能映射 1.5-2G 的文件至用户态的虚拟内存,故 RocketMQ 的文件存储都使用定长结构来存储(单个 CommitLog 日志数据文件为 1G),方便一次将整个文件映射至内存。
mmap缺点:当另一个进程截断同一文件时,比如调用truncate,调用write,此时的write系统调用将被总线错误信号SIGBUS打断,因为你执行了一个错误的内存访问。该信号的默认行为是杀死进程并dumpcore。
2、sendfile
sendfile 系统调用在 Linux 内核版本 2.1 中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程。sendfile 系统调用的引入,不仅减少了 CPU 拷贝的次数,还减少了上下文切换的次数,它的伪代码如下:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);

通过 sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。与 mmap 内存映射方式不同的是, sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。
基于 sendfile(), 整个数据传输过程中共发生 2 次 DMA 拷贝和 1 次 CPU 拷贝,这个和 mmap() + write() 相同,但是因为 sendfile() 只是一次系统调用,因此比前者少了用户态和内核态的上下文切换开销。
优点:减少了数据拷贝次数以及系统调用次数。
缺点:不能对数据进行修改,只能是一次单纯的数据传输过程,适合于静态文件传输。
sendfile仍然需要进行一次从内核缓冲区到Socket缓冲区的拷贝。因此,为了将仅有的一次CPU拷贝也去掉,在Linux2.4引入了sendile with DMA Scatter/Gather Copy。

- 用户进程调用 sendfile(),从用户态陷入内核态;
- DMA 控制器使用 scatter 功能把数据从磁盘拷贝到内核缓冲区进行离散存储;
- CPU 把包含内存地址和数据长度的缓冲区描述符拷贝到套接字缓冲区,DMA 控制器能够根据这些信息生成网络包数据分组的报头和报尾
- DMA 控制器根据缓冲区描述符里的内存地址和数据大小,使用 scatter-gather 功能开始从内核缓冲区收集离散的数据并组包,最后直接把网络包数据拷贝到网卡完成数据传输;
- sendfile() 返回,上下文从内核态切换回用户态。
优点:进一步减少CPU数据拷贝的次数;
缺点:需要硬件支持。
3、splice
Linux在2.6.17中引入了splice系统调用。和sendfile一样,其在数据传输过程中,避免了CPU的数据拷贝,此外也不需要硬件支持。

- 用户进程系统调用pipe(),从用户态切换到内核态,创建单向管道,从内核态切换会用户态。
- 调用splice() 向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从磁盘拷贝到内核缓冲区,从管道写入端“写入”管道。splice返回,从内核态切换回用户态。
- 再次调用splice,CPU将数据从管道拷贝到Socket缓冲区。
- CPU 利用 DMA 控制器将数据从Socket缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),splice 系统调用执行返回。
splice是基于pipe buffer机制实现的,因为必须有一个要是管道设备。
管道就是一个特殊的文件,一个实现FIFO的队列,有匿名管道和命名管道。
创建匿名管道:
匿名管道(父子进程):grep -rl "xiaomi" | wc -l命名管道:
mkfifo namedpipe
echo "xiaomiyoupin" > namedpipe另一个进程:cat namedpipe
相比于sendfile,其多了一个pipe系统调用,有两次的splice调用,增加了上下文切换次数。但它在写入读出时并没有使用 pipe_write()/pipe_read() 真正地在管道缓冲区写入读出数据,而是通过把数据在内存缓冲区中的物理内存页框指针、偏移量和长度赋值给前文提及的 pipe_buffer 中对应的三个字段来完成数据的"拷贝",也就是其实只拷贝了数据的内存地址等元信息。
优点:在实现了“零次”CPU拷贝的情况下,不需要硬件支持。
缺点:因为其是基于管道的,管道是固定大小的缓冲区,因此在每次传输上是有字节数的限制的。此外,每次系统调用都会创建pipe,频繁调用影响性能。
优化方案:通过pipe pool避免频繁创建pipe,比如HAProxy。
3、写时复制
COW(Copy on Write), 在Linux中,通过 fork 系统调用创建子进程时,并不会把父进程所有占用的内存页复制一份,而是与父进程共用相同的内存页,而当子进程或者父进程对内存页进行修改时才会进行复制 。
fork子进程时,将父进程的虚拟内存与物理内存映射关系复制到子进程中,并将内存设置为只读(设置为只读是为了当对内存进行写操作时触发 缺页异常)。
当子进程或者父进程对内存数据进行修改时,便会触发 写时复制 机制:将原来的内存页复制一份新的,并重新设置其内存映射关系,将父子进程的内存读写权限设置为可读写。
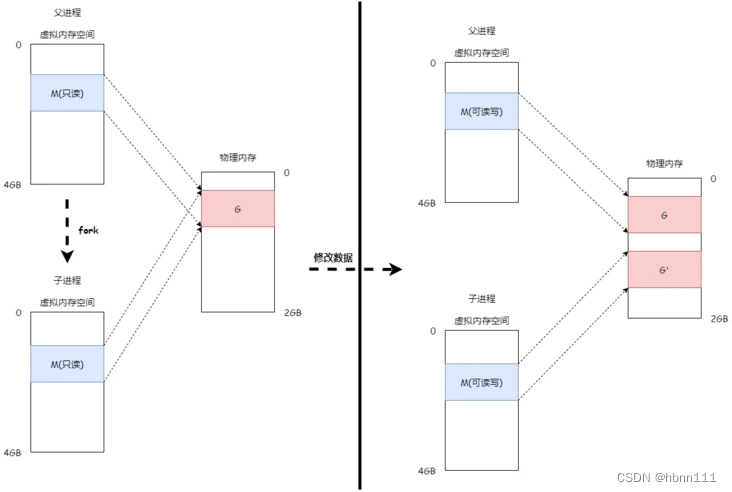
优点:减少内存的占用
一个典型的例子:Redis的bgsave持久化命令。
三、零拷贝实践
实现功能:Socket网络文件传输。SocketServer负责网络数据接收;Client分别实现零拷贝和传统数据传输。
实验机器配置:Ubuntu20.04 8 CPU+16G内存
传输数据大小:1.9G(已存在内核缓存数据的情况下),每个客户端传输10次。
1)SocketServer.py:
"""* =======================================* @Author : haibo* @Email : wanghaibo6* @File : server.py* =======================================
"""import socket
import timeBUFFER_SIZE = 8 * 1024class Server:def __init__(self, ip, port):self.server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)self.server.bind((ip, port))def start(self):self.server.listen(5)print("Server started SuccessFully")while True:client_socket, addr = self.server.accept()print("new socket:", addr)start = time.time()while True:data = client_socket.recv(BUFFER_SIZE)if not data:breakclient_socket.close()print("Server received finished. it costs:", time.time() - start)if __name__ == "__main__":server = Server("127.0.0.1", 6667)server.start()
2)非零拷贝client.py
"""* =======================================* @Author : haibo* @Email : wanghaibo6* @File : common_client.py* =======================================
"""import socket
import timeCHUNK_SIZE = 8 * 1024def send_file_by_socket():client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)client.connect(('127.0.0.1', 6667))start = time.time()i = 0while i < 10:with open("/home/haibo/baseserver.zip", "rb") as f:print("Start to send file")data = f.read(CHUNK_SIZE)while data:client.send(data)data = f.read(CHUNK_SIZE)i += 1end = time.time()print("transfer finish")print("it cost:", end - start)send_file_by_socket()
3)零拷贝client.py
"""* =======================================* @Author : haibo* @Email : wanghaibo6* @File : zerocopy_client.py* =======================================
"""import socket
import time
import osCHUNK_SIZE = 8 * 1024def send_file_by_socket():client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)client.connect(('127.0.0.1', 6667))start = time.time()i = 0while i < 10:with open("/home/haibo/baseserver.zip", "rb") as f:print("Start to send file")ret = offset = 0while True:ret = os.sendfile(client.fileno(), f.fileno(), offset, CHUNK_SIZE)if ret == 0:breakoffset += reti += 1end = time.time()print("transfer finish")print("it cost:", end - start)send_file_by_socket()
性能对比(存在缓存的情况下):
| common_client.py | zerocopy_client.py |
| 10.1201s | 5.7624s |
| 10.3032s | 5.9959s |
| 9.8249s | 6.1553s |
从实验结果上可知,通过零拷贝技术使得网络文件传输的性能上得到了极大的提升!
四、总结
零拷贝技术主要目的在于优化IO传输性能,由于其能极大提升IO传输效率,得到了广泛的使用,尤其是当今的应用几乎属于IO密集型应用。目前,Netty,Rocketmq,Nginx,HAproxy,Kafka,lettuce等优秀的框架以及基础组件都有所使用。
本文介绍了几种不同的零拷贝技术,不同的分类有着不同的业务场景。比如mmap更适合于大文件的传输;sendfile更适合于静态文件的传输;直接IO更适合于实现自缓存的应用等。在实际应用中,可根据自身的业务特点来做选择。
参考资料:
深入剖析Linux IO原理和几种零拷贝机制的实现 - 知乎
Linux I/O 原理和 Zero-copy 技术全面揭秘 - 知乎
浅谈Linux内核IO体系之磁盘IO - 知乎
Linux 中直接 I/O 机制的介绍_DivineH的博客-CSDN博客
RocketMQ源码分析(六)之Broker存储MappedFile_jannals的博客-CSDN博客
零拷贝(Zero-copy)及其应用详解 - 简书





![[NPUCTF2020]ezinclude ---不会编程的崽](https://img-blog.csdnimg.cn/direct/40f162b34b2a4f16a8722727d0b7f548.png)