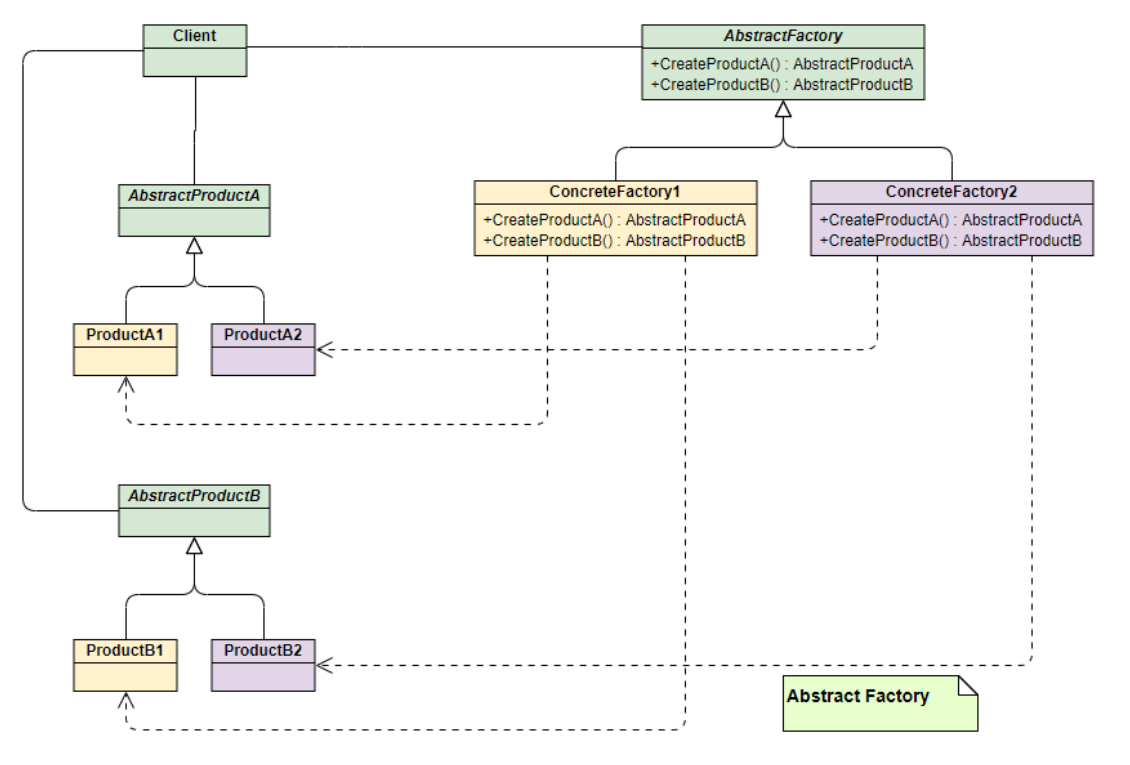
选择最佳数据序列化格式:找到适合您的解决方案
前言
在当今数据驱动的世界中,高效地处理和传输数据变得至关重要。选择合适的数据序列化格式对于数据存储、通信和处理的性能至关重要。本文将介绍并比较几种常用的数据序列化格式,包括Apache Avro、Protocol Buffers、JSON、XML、MessagePack和BSON。通过了解它们的概述、特点、应用场景和示例代码,您将能够更好地选择适合您需求的数据序列化格式。
欢迎订阅专栏:Java万花筒
文章目录
- 选择最佳数据序列化格式:找到适合您的解决方案
- 前言
- 1. Apache Avro
- 1.1 概述
- 1.2 特点
- 1.3 应用场景
- 1.4 其他特性
- 1.5 Avro序列化和反序列化的使用方法
- 1.5.1 序列化
- 1.5.2 反序列化
- 1.6 参考链接
- 2. Protocol Buffers (protobuf)
- 2.1 概述
- 2.2 特点
- 2.2.1 紧凑性
- 2.2.2 可扩展性
- 2.2.3 速度
- 2.3 应用场景
- 2.4 其他特性
- 2.5 Protocol Buffers序列化和反序列化的使用方法
- 2.5.1 序列化
- 2.5.2 反序列化
- 2.6 参考链接
- 3. JSON (JavaScript Object Notation)
- 3.1 概述
- 3.2 特点
- 3.2.1 简洁易读
- 3.2.2 跨语言支持
- 3.2.3 可扩展性
- 3.3 应用场景
- 3.4 其他特性
- 3.5 JSON库的使用方法
- 3.5.1 序列化
- 3.5.2 反序列化
- 3.6 参考链接
- 4. XML (eXtensible Markup Language)
- 4.1 概述
- 4.2 特点
- 4.2.1 结构化数据
- 4.2.2 可扩展性
- 4.2.3 跨平台兼容性
- 4.3 应用场景
- 4.4 其他特性
- 4.5 XML库的使用方法
- 4.5.1 解析XML
- 4.6 参考链接
- 5. MessagePack
- 5.1 概述
- 5.2 特点
- 5.2.1 二进制格式
- 5.2.2 快速编码解码
- 5.2.3 跨语言支持
- 5.3 应用场景
- 5.4 Java示例代码
- 5.5 其他特性
- 5.6 参考链接
- 6. BSON (Binary JSON)
- 6.1 概述
- 6.2 特点
- 6.2.1 二进制格式
- 6.2.2 支持数据类型
- 6.2.3 跨语言支持
- 6.3 应用场景
- 6.4 Java示例代码
- 6.5 其他特性
- 6.6 参考链接
- 总结
1. Apache Avro
1.1 概述
Apache Avro是一种二进制的数据序列化格式,旨在提供快速、高效的大数据处理方式。它支持动态类型、自我描述和跨语言通信。
1.2 特点
- 动态类型:Avro使用schema来定义数据结构,使数据能够在读取时进行解释,从而实现动态类型。
- 自我描述:数据序列化时,schema信息会被包含在序列化数据中,使得数据能够独立自我描述,无需外部定义。
- 跨语言支持:Avro提供了多种编程语言的支持,使得不同语言的应用程序可以进行跨语言的数据交换。
1.3 应用场景
- 大数据处理:Avro的高效性和自我描述的特点使其成为处理大数据的理想选择。它能够快速序列化和反序列化大量数据,同时支持动态类型,适用于大数据分析、存储和传输等场景。
以下是使用Apache Avro的Java示例代码:
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumReader;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import java.io.File;
import java.io.IOException;public class AvroExample {public static void main(String[] args) throws IOException {// 定义Avro SchemaString schemaString = "{\"type\":\"record\",\"name\":\"Person\",\"fields\":[{\"name\":\"name\",\"type\":\"string\"},{\"name\":\"age\",\"type\":\"int\"}]}";Schema.Parser parser = new Schema.Parser();Schema schema = parser.parse(schemaString);// 创建GenericRecord对象GenericRecord person = new GenericData.Record(schema);person.put("name", "John");person.put("age", 30);// 将数据写入Avro文件DataFileWriter<GenericRecord> writer = new DataFileWriter<>(new GenericDatumWriter<>(schema));writer.create(schema, new File("person.avro"));writer.append(person);writer.close();// 从Avro文件中读取数据DatumReader<GenericRecord> reader = new GenericDatumReader<>(schema);DataFileReader<GenericRecord> fileReader = new DataFileReader<>(new File("person.avro"), reader);while (fileReader.hasNext()) {GenericRecord record = fileReader.next();System.out.println("Name: " + record.get("name"));System.out.println("Age: " + record.get("age"));}fileReader.close();}
}
1.4 其他特性
除了上述介绍的特点之外,Apache Avro还具有以下特性:
- 易于使用:Avro提供简单的API和丰富的文档,使得使用者可以快速上手并灵活地进行开发。
- 高效的数据压缩:Avro使用二进制格式进行数据序列化,具有较高的压缩比,从而减少数据传输和存储的成本。
- 架构演化:Avro支持架构演化,允许在不中断生产者和消费者之间的数据交换的情况下进行架构的修改和升级。
- 可扩展性:Avro的schema支持添加新的字段和修改现有字段,使得数据模型能够适应新的需求和变化。
1.5 Avro序列化和反序列化的使用方法
Avro为不同编程语言提供了序列化和反序列化的API,下面以Java为例介绍Avro序列化和反序列化的使用方法。
1.5.1 序列化
在Avro中,使用GenericDatumWriter和DataFileWriter来将数据序列化为Avro格式并写入Avro文件。下面是序列化的示例代码:
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import java.io.File;
import java.io.IOException;public class AvroSerializationExample {public static void main(String[] args) {// 定义Avro SchemaString schemaString = "{\"type\":\"record\",\"name\":\"Person\",\"fields\":[{\"name\":\"name\",\"type\":\"string\"},{\"name\":\"age\",\"type\":\"int\"}]}";Schema.Parser parser = new Schema.Parser();Schema schema = parser.parse(schemaString);// 创建GenericRecord对象GenericRecord person = new GenericData.Record(schema);person.put("name", "John");person.put("age", 30);// 将数据写入Avro文件try (DataFileWriter<GenericRecord> writer = new DataFileWriter<>(new GenericDatumWriter<>(schema))) {writer.create(schema, new File("person.avro"));writer.append(person);System.out.println("数据序列化成功!");} catch (IOException e) {e.printStackTrace();}}
}
在这个示例中,我们首先定义了Avro的Schema,然后创建了一个GenericRecord对象,将数据填充到对象中。接下来,我们使用DataFileWriter将GenericRecord对象写入到Avro文件中。
1.5.2 反序列化
在Avro中,使用GenericDatumReader和DataFileReader来从Avro文件中读取并反序列化数据。下面是反序列化的示例代码:
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.generic.GenericDatumReader;
import org.apache.avro.generic.GenericRecord;
import java.io.File;
import java.io.IOException;public class AvroDeserializationExample {public static void main(String[] args) {// 从Avro文件中读取数据try (DataFileReader<GenericRecord> fileReader = new DataFileReader<>(new File("person.avro"), new GenericDatumReader<>())) {Schema schema = fileReader.getSchema();while (fileReader.hasNext()) {GenericRecord record = fileReader.next();String name = record.get("name").toString();int age = (int) record.get("age");System.out.println("Name: " + name);System.out.println("Age: " + age);}} catch (IOException e) {e.printStackTrace();}}
}
在这个示例中,我们使用DataFileReader从Avro文件中读取数据,并使用GenericRecord对象获取记录中的字段值。然后,我们将获取到的字段值打印出来。
1.6 参考链接
- Apache Avro官方网站
- Avro Java API文档
2. Protocol Buffers (protobuf)
2.1 概述
Protocol Buffers是由Google开发的一种二进制序列化格式,用于结构化数据的存储和通信。它基于schema定义数据结构,并生成用于不同编程语言的代码。
2.2 特点
2.2.1 紧凑性
Protocol Buffers使用二进制格式进行数据序列化,相比于文本格式,具有更高的紧凑性,能够节省存储空间和网络带宽。
2.2.2 可扩展性
Protocol Buffers的schema定义了数据结构,支持向后和向前兼容的扩展。可以在不破坏现有代码的前提下,向数据结构添加新字段。
2.2.3 速度
由于使用了紧凑的二进制格式和生成的高效代码,Protocol Buffers具有较高的编码和解码速度,适用于高性能场景。
2.3 应用场景
- 分布式系统间的数据交换:Protocol Buffers提供了多语言支持,适用于跨语言的数据通信,可用于构建分布式系统中不同节点间的数据交换。
- 数据存储:由于紧凑的二进制格式和高性能特性,Protocol Buffers适合用于存储大量结构化数据,如日志、配置信息等。
以下是使用Protocol Buffers的Java示例代码:
import com.example.PersonOuterClass.Person;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;public class ProtobufExample {public static void main(String[] args) throws IOException {// 创建Person对象Person person = Person.newBuilder().setName("John").setAge(30).build();// 将数据写入Protobuf文件FileOutputStream output = new FileOutputStream("person.proto");person.writeTo(output);output.close();// 从Protobuf文件中读取数据FileInputStream input = new FileInputStream("person.proto");Person personFromFile = Person.parseFrom(input);input.close();// 输出读取的数据System.out.println("Name: " + personFromFile.getName());System.out.println("Age: " + personFromFile.getAge());}
}
在这个示例中,我们首先使用Protocol Buffers的定义文件(.proto)生成了Java代码。然后,我们创建了一个Person对象,并设置了姓名和年龄。接下来,我们将这个对象写入到Protobuf文件中,然后从文件中读取数据并打印出来。
2.4 其他特性
除了上述介绍的特点之外,Protocol Buffers还具有以下特性:
- 跨平台支持:Protocol Buffers提供了多种语言的支持,包括C++、Java、Python等,使得不同平台上的应用程序可以进行数据交换。
- 易于更新:通过向schema中添加新字段或更改现有字段,可以轻松更新数据结构,而无需更改现有代码。
- 自描述:Protocol Buffers的消息中包含字段的标识符和类型信息,使得数据能够自我描述,无需外部定义。
- 对象关系映射(ORM):Protocol Buffers支持对象关系映射,可以将结构化数据映射到面向对象的模型中。
2.5 Protocol Buffers序列化和反序列化的使用方法
Protocol Buffers提供了序列化和反序列化的API,下面是Java中使用Protocol Buffers进行序列化和反序列化的示例代码:
2.5.1 序列化
在Protocol Buffers中,使用生成的Builder类来构建消息对象,并使用writeTo方法将消息对象序列化为二进制数据。以下是序列化的示例代码:
import com.example.PersonOuterClass.Person;
import java.io.FileOutputStream;
import java.io.IOException;public class ProtobufSerializationExample {public static void main(String[] args) throws IOException {// 创建Person对象Person person = Person.newBuilder().setName("John").setAge(30).build();// 将数据写入Protobuf文件FileOutputStream output = new FileOutputStream("person.proto");person.writeTo(output);output.close();System.out.println("数据序列化成功!");}
}
在这个示例中,我们使用生成的Builder类创建了一个Person对象,并设置了姓名和年龄。然后,我们将这个对象写入到Protobuf文件中。
2.5.2 反序列化
在Protocol Buffers中,使用生成的parseFrom方法从二进制数据中反序列化消息对象。以下是反序列化的示例代码:
import com.example.PersonOuterClass.Person;
import java.io.FileInputStream;
import java.io.IOException;public class ProtobufDeserializationExample {public static void main(String[] args) throws IOException {// 从Protobuf文件中读取数据FileInputStream input = new FileInputStream("person.proto");Person personFromFile = Person.parseFrom(input);input.close();// 输出读取的数据System.out.println("Name: " + personFromFile.getName());System.out.println("Age: " + personFromFile.getAge());}
}
在这个示例中,我们使用parseFrom方法从Protobuf文件中读取数据,并将其反序列化为Person对象。然后,我们从反序列化后的对象中获取姓名和年龄,并进行打印。
2.6 参考链接
- Protocol Buffers官方网站
- Protocol Buffers Java Tutorial
3. JSON (JavaScript Object Notation)
3.1 概述
JSON是一种轻量级的数据交换格式,以易读的文本格式表示结构化数据。它由一组键值对构成,使用大括号包裹。在Java中,可以使用各种JSON库进行解析和生成JSON数据。
3.2 特点
3.2.1 简洁易读
JSON使用简洁的文本格式表示数据,易于阅读和理解,同时也方便进行调试和开发。
3.2.2 跨语言支持
JSON在各种编程语言中都有广泛支持,可以轻松实现不同语言之间的数据交换。
3.2.3 可扩展性
JSON支持嵌套结构和复杂数据类型,可以表示更复杂的数据结构,并支持自定义数据格式。
3.3 应用场景
- Web API数据交换:JSON是Web开发中常用的数据交换格式,用于前后端数据交互和API调用。
- 配置文件:JSON格式可以用于存储配置信息,方便解析和修改。
以下是使用JSON库(Gson)的Java示例代码:
import com.google.gson.Gson;
import java.util.HashMap;
import java.util.Map;public class JsonExample {public static void main(String[] args) {// 创建一个Java对象Map<String, Object> person = new HashMap<>();person.put("name", "John");person.put("age", 30);// 将Java对象转换为JSON字符串Gson gson = new Gson();String json = gson.toJson(person);System.out.println(json);// 将JSON字符串转换为Java对象Map<String, Object> personFromJson = gson.fromJson(json, Map.class);System.out.println("Name: " + personFromJson.get("name"));System.out.println("Age: " + personFromJson.get("age"));}
}
在这个示例中,我们首先创建了一个Java对象(使用Map表示),并设置了姓名和年龄。然后,我们使用Gson库将这个Java对象转换为JSON字符串,并打印出来。接下来,我们将JSON字符串转换回Java对象,并从中获取姓名和年龄进行打印。
3.4 其他特性
除了上述介绍的特点之外,JSON还具有以下特性:
- 平台无关性:由于JSON是一种文本格式,因此可以在各种平台上使用,不受语言限制。
- 易于解析和生成:JSON数据可以很容易地解析为对象或生成为JSON字符串,许多编程语言提供了方便的API。
- 可读性强:相比于二进制格式,JSON的文本表示更容易被人类读懂,方便调试和开发。
3.5 JSON库的使用方法
Java中有多个JSON库可供选择,常见的有Gson、Jackson、JSON-lib等。以下是使用Gson库进行JSON序列化和反序列化的示例代码:
3.5.1 序列化
在Gson中,可以使用toJson方法将Java对象序列化为JSON字符串。以下是序列化的示例代码:
import com.google.gson.Gson;public class JsonSerializationExample {public static void main(String[] args) {// 创建一个Java对象Person person = new Person("John", 30);// 将Java对象转换为JSON字符串Gson gson = new Gson();String json = gson.toJson(person);System.out.println(json);}
}
在这个示例中,我们首先创建了一个Java对象(Person类),然后使用Gson的toJson方法将这个Java对象转换为JSON字符串。
3.5.2 反序列化
在Gson中,可以使用fromJson方法将JSON字符串反序列化为Java对象。以下是反序列化的示例代码:
import com.google.gson.Gson;public class JsonDeserializationExample {public static void main(String[] args) {// JSON字符串String json = "{\"name\":\"John\",\"age\":30}";// 将JSON字符串转换为Java对象Gson gson = new Gson();Person person = gson.fromJson(json, Person.class);// 输出读取的数据System.out.println("Name: " + person.getName());System.out.println("Age: " + person.getAge());}
}
在这个示例中,我们首先定义了一个JSON字符串,然后使用Gson的fromJson方法将JSON字符串反序列化为Java对象(Person类)。然后,我们从反序列化后的对象中获取姓名和年龄,并进行打印。
3.6 参考链接
- Gson官方文档
- Jackson官方网站
- JSON-lib官方网站
4. XML (eXtensible Markup Language)
4.1 概述
XML是一种通用的标记语言,用于描述和传输结构化数据。它使用标签来定义数据的结构和语义,具有良好的可读性和可扩展性。
4.2 特点
4.2.1 结构化数据
XML可以表示复杂的结构化数据,通过标签和属性来定义数据的层次结构和关系。
4.2.2 可扩展性
XML的结构可以根据需要自定义,支持自定义标签和属性,适应不同的数据要求。
4.2.3 跨平台兼容性
XML是一种独立于平台和编程语言的数据格式,可以在不同系统和应用程序之间进行数据交换。
4.3 应用场景
- 数据传输和存储:XML常用于数据传输和存储,特别是在跨平台和跨语言的环境中,XML能够保持数据的结构和语义。
- 配置文件:XML格式广泛用于配置文件,如在Java中的Spring配置文件和Web应用程序的部署描述文件等。
以下是使用Java内置XML库(javax.xml)的示例代码:
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;public class XmlExample {public static void main(String[] args) throws Exception {// 解析XML文件File xmlFile = new File("person.xml");DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document document = builder.parse(xmlFile);// 获取根元素Element rootElement = document.getDocumentElement();// 获取所有Person元素NodeList personNodes = rootElement.getElementsByTagName("Person");for (int i = 0; i < personNodes.getLength(); i++) {Element personElement = (Element) personNodes.item(i);String name = personElement.getAttribute("name");int age = Integer.parseInt(personElement.getAttribute("age"));System.out.println("Name: " + name);System.out.println("Age: " + age);}}
}
这些是常见的消息格式化方式和相应的Java示例代码。根据需求和场景的不同,可以选择适合的消息格式化方式来实现数据的存储、传输和解析。
在这个示例中,我们首先使用Java内置的XML库(javax.xml)解析了一个XML文件。然后,我们获取了XML文件的根元素,并通过标签名称获取了所有的Person元素。对于每个Person元素,我们获取了其name和age属性,并进行打印。
4.4 其他特性
除了上述介绍的特点之外,XML还具有以下特性:
- 可读性强:XML使用标签和属性来描述数据,具有良好的可读性,方便人类阅读和理解。
- 可扩展性:XML支持自定义标签和属性,可以根据需要进行扩展,适应不同的数据要求。
- 数据独立性:XML数据是与平台和编程语言无关的,可以在不同系统和应用程序之间进行数据交换。
- 支持验证:XML支持使用DTD(文档类型定义)或XML Schema进行数据验证,确保数据的有效性和一致性。
4.5 XML库的使用方法
在Java中,有多个XML库可供选择,常见的有javax.xml、dom4j、JDOM等。以下是使用javax.xml库进行XML解析的示例代码:
4.5.1 解析XML
在javax.xml中,可以使用DocumentBuilder和Document类来解析XML文件。以下是解析XML的示例代码:
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;public class XmlParsingExample {public static void main(String[] args) throws Exception {// 解析XML文件File xmlFile = new File("data.xml");DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document document = builder.parse(xmlFile);// 获取根元素Element rootElement = document.getDocumentElement();// 获取所有Person元素NodeList personNodes = rootElement.getElementsByTagName("Person");for (int i = 0; i < personNodes.getLength(); i++) {Element personElement = (Element) personNodes.item(i);String name = personElement.getAttribute("name");int age = Integer.parseInt(personElement.getAttribute("age"));System.out.println("Name: " + name);System.out.println("Age: " + age);}}
}
在这个示例中,我们使用DocumentBuilder和Document类来解析XML文件,并获取根元素和Person元素。然后,我们从每个Person元素中获取name和age属性,并进行打印。
4.6 参考链接
- XML官方网站
- javax.xml官方文档
- dom4j官方网站
- JDOM官方网站
5. MessagePack
5.1 概述
MessagePack是一种高效的二进制数据序列化格式,旨在提供比JSON更高的性能和更小的数据大小。它采用简单的键值对格式,并支持多种数据类型。
5.2 特点
5.2.1 二进制格式
MessagePack使用二进制编码,相对于文本格式的JSON,可以显著减小数据的大小。
5.2.2 快速编码解码
MessagePack的编码解码速度非常快,比JSON更高效。
5.2.3 跨语言支持
MessagePack支持众多编程语言,如Java、Python、C++等,可以在不同语言之间进行数据交换。
5.3 应用场景
- 数据传输和存储:MessagePack适用于需要高性能和较小数据大小的数据传输和存储场景。
- 分布式系统间的通信:MessagePack可用于分布式系统之间的消息传递,提高通信效率。
5.4 Java示例代码
以下是一个使用Java的MessagePack库实现数据的编码和解码的示例代码:
import org.msgpack.core.MessageBufferPacker;
import org.msgpack.core.MessagePack;
import org.msgpack.core.MessageUnpacker;
import java.io.IOException;public class MessagePackExample {public static void main(String[] args) throws IOException {// 创建MessagePack对象MessagePack messagePack = new MessagePack();// 编码数据MessageBufferPacker packer = messagePack.newBufferPacker();packer.packString("John");packer.packInt(30);byte[] encodedData = packer.toByteArray();// 解码数据MessageUnpacker unpacker = messagePack.newUnpacker(encodedData);String name = unpacker.unpackString();int age = unpacker.unpackInt();// 输出解码后的数据System.out.println("Name: " + name);System.out.println("Age: " + age);}
}
请注意,为了运行以上代码,需要使用MessagePack库。您可以使用以下依赖项将其添加到Maven项目中:
<dependency><groupId>org.msgpack</groupId><artifactId>msgpack-core</artifactId><version>0.8.21</version>
</dependency>
在这个示例中,我们首先创建了一个MessagePack对象,然后使用它创建一个编码器(packer)来编码数据。我们使用packString方法和packInt方法将数据编码为MessagePack格式。编码后,我们将编码数据转换为字节数组,并将其传递给解码器(unpacker)。然后,我们使用unpackString方法和unpackInt方法从解码器中解码数据。最后,我们将解码后的数据进行打印。
5.5 其他特性
除了上述介绍的特点之外,MessagePack还具有以下特性:
- 跨平台兼容性:MessagePack是一种跨平台的数据格式,可以在不同操作系统和编程语言之间进行数据交换。
- 支持多种数据类型:MessagePack支持多种数据类型,如整数、浮点数、字符串、布尔值、数组、映射等。
- 易于使用:MessagePack提供了简单易用的API,使得编码和解码过程简单明了。
5.6 参考链接
- MessagePack官方网站
- msgpack-core官方文档
6. BSON (Binary JSON)
6.1 概述
BSON是一种二进制JSON格式,设计用于高效地表示和存储文档数据。它是MongoDB数据库的默认数据存储格式。
6.2 特点
6.2.1 二进制格式
BSON使用二进制编码,比JSON更紧凑,适合存储和传输大量结构化数据。
6.2.2 支持数据类型
BSON支持丰富的数据类型,包括字符串、整数、浮点数、数组、对象等。
6.2.3 跨语言支持
BSON支持多种编程语言,使得不同语言的应用程序可以轻松地读写和解析BSON数据。
6.3 应用场景
- MongoDB数据库:BSON是MongoDB数据库的原生数据存储格式,在存储文档数据时非常高效。
- 缓存系统:BSON可以用于缓存系统,将数据以二进制形式存储,提高读写速度。
6.4 Java示例代码
以下是一个使用Java的BSON库实现数据的编码和解码的示例代码:
import org.bson.BsonDocument;
import org.bson.BsonInt32;
import org.bson.BsonString;
import org.bson.BsonValue;
import org.bson.Document;
import org.bson.codecs.configuration.CodecRegistry;
import org.bson.codecs.pojo.PojoCodecProvider;
import org.bson.conversions.Bson;
import org.bson.json.JsonMode;
import org.bson.json.JsonWriterSettings;
import org.bson.types.ObjectId;import java.util.Arrays;
import java.util.List;import static java.util.Arrays.asList;public class BSONExample {public static void main(String[] args) {// 创建BSON文档Document document = new Document("_id", new ObjectId()).append("name", "John").append("age", 30).append("hobbies", Arrays.asList("reading", "cooking"));// 将BSON文档转换为JSON字符串JsonWriterSettings settings = JsonWriterSettings.builder().outputMode(JsonMode.STRICT).build();String json = document.toJson(settings);System.out.println("BSON to JSON:\n" + json);// 将JSON字符串转换为BSON文档Document bsonDocument = Document.parse(json);System.out.println("JSON to BSON:\n" + bsonDocument);// 对BSON文档进行查询Bson query = new BsonDocument("age", new BsonInt32(30));System.out.println("Query: " + query);}
}
请注意,为了运行以上代码,需要使用BSON库。您可以使用以下依赖项将其添加到Maven项目中:
<dependency><groupId>org.mongodb</groupId><artifactId>bson</artifactId><version>4.3.1</version>
</dependency>
在这个示例中,我们首先创建了一个BSON文档,使用Document类来表示。我们为文档添加了不同类型的字段,包括ObjectId、String、int和List。然后,我们使用toJson方法将BSON文档转换为JSON字符串,并通过JsonWriterSettings指定输出模式。接下来,我们使用parse方法将JSON字符串转换回BSON文档。最后,我们创建了一个查询条件,并将其打印出来。
6.5 其他特性
除了上述介绍的特点之外,BSON还具有以下特性:
- 内置支持日期和时间类型:BSON支持内置的日期和时间类型,如
Date和Timestamp,方便存储和处理时间相关数据。 - 可嵌套的文档结构:BSON支持嵌套的文档结构,可以在一个文档中嵌套另一个文档,实现更复杂的数据结构。
- 扩展性:BSON支持自定义数据编码和解码规则,可以扩展以支持特定的数据类型和需求。
6.6 参考链接
- BSON官方网站
- bson官方文档
总结
本文详细介绍了几种常用的数据序列化格式,包括Apache Avro、Protocol Buffers、JSON、XML、MessagePack和BSON,以帮助您选择最适合您需求的格式。我们从每种格式的概述、特点和应用场景入手,并提供了相关的示例代码来帮助您更好地理解和应用这些格式。无论是在大数据处理、分布式系统通信还是API数据交互方面,选择正确的数据序列化格式至关重要。希望本文能够为您提供有价值的信息,帮助您做出明智的决策。