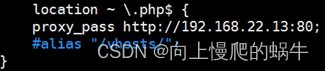
最近,阿里巴巴又推出了一款AI视频新框架——EMO。

特点及官方演示
EMO的功能特点如下:
1.音频驱动的视频生成:根据输入的音频(如说话或唱歌)和参考图像,生成具有表情变化和头部动作的虚拟角色视频。
2.多语言支持:支持多种语言的音频输入,能够为不同语言的歌曲生成相应的表情和动作。
3.表情和动作同步:确保生成的视频中的角色表情和头部动作与音频输入的节奏和情感相匹配。
5.跨文化和多语言应用:在多语言和多文化背景下,为角色提供表演和独白的能力。
最近AI美女的舞蹈非常火,抖音上我们看下其中的效果,这种也是用AI做的。
还有下面这个:
你没看错,以上的视频是由人工智能生成的。这样的视频非常引人注目,能够吸引人的注意。一个博主利用这个美女视频,在短短一周内就吸引了3万多粉丝,并且一个月的收入达到了几千。
是不是非常的惹人注目,吸引眼球?有一个博主通过这个美女视频,在一周时间就收获了3万多粉丝,一个月收益大几千。

音中的发音和语调是生成肖像运动的主要驱动信号。在音频注意层,从输入音频中提取出的特征通过预训练的语音识别模型Wav2vec进行连接,得到每一帧的音频表示嵌入。为了计算运动受未来/过去音频片段的影响,例如说话前的张嘴和吸气,作者通过串联附近帧的特征来定义每个生成帧的语音特征。
大多数模型都会在预训练的文本到图像架构中插入时序混合层,以促进对连续视频帧之间时间关系的理解和编码。受文生视频框架AnimateDiff架构概念的启发,EMO将自关注时序层应用于帧内特征。具体来说,EMO将输入特征图重构,在时序维度上进行自我关注,以有效捕捉视频的动态内容,时序层被插入主干网络的每个分辨率层。
在视频时长方面,受一些方法采用前一个片段结尾的帧作为后续生成初始帧的启发,EMO采用了前一个生成片段的最后n个帧,称之为“运动帧”(Motion frames),将其输入参考网络,以预提取多分辨率运动特征图。在主干网络的去噪过程中,EMO会将时序层输入与预提取的运动特征图进行合并,从而有效确保不同片段之间的一致性。
值得注意的是,虽然主干网络可能会反复多次对噪声帧进行去噪处理,但目标图像和运动帧只需连接一次并输入参考网络。因此,提取的特征会在整个过程中重复使用,确保推理过程中的计算时间不会大幅增加。
项目主页:
https://humanaigc.github.io/emote-portrait-alive/
GitHub地址:
https://github.com/HumanAIGC/EMO
需要代充或者买成品号Plus/Midjourney玩AI创作的可以加v:amo198905或者扫下面二维码加v。私聊预订Plus/Midjourney号,加v时备注:Plus/Midjourney。